

Summary: A good training course that succeeded in teaching me how to deploy and manage a simple Docker Datacenter environment, as well as giving me some insight into the product itself.
Earlier this month I was lucky enough to take the beta training for Docker’s recently released Datacenter product. Being a beta it was offered for free (thankyou Docker!) although spaces were limited due to the courses being instructor led. There were only nine students on my course so it was quite personal, and despite being marketed for those in the US the attendees were from multiple timezones – one guy was doing it at 3am local time – so there’s obviously demand for training.
The attendees were from mixed backgrounds – interestingly most identified themselves as DevOps engineers or operations whereas I expected more developers. Levels of experience with Docker also varied from beginner to expert but all were able to complete the training successfully. I should state that while I’m not a complete beginner I’m certainly no expert either when it comes to Docker and containers.
The training consisted of three sessions, each four hours long, set over consecutive weeks. The course was offered online which is what made it possible for those like me working in remote places. It was about 80% hands on and 20% lecture time and the prerequisites are pretty simple – know what Docker is, how to pull and run container images, know Linux fundamentals (ssh, scp, navigating folders) etc. The training itself was similar to the training available at DockerConEU which is to say it uses AWS instances and content publicly available on Github. This is nice as it lets you have a look at some of the content in advance (in case you want to prepare or read up on some topics as I did) or after the course as a recap. It might be self explanatory enough to work through on your own, but be aware some sections have prerequisites which you’d need to setup yourself (rather than being provided them via AWS instances as we were). I received an email a few hours in advance of the course with a link to the online conference along with details of my AWS instances.
The presentations were simple overviews of the Docker products along with some background concepts, such as microservices. There were done in Reveal.js (which is pretty slick and worth learning, tutorial here) and had been containerised, meaning you can quickly and easily download it and run it locally (which could be useful for those that want to explore further at a later date);
docker pull training/docker-present docker run --ti --rm -v /var/run/docker.sock:/var/run/docker.sock training/docker-present -p 8080
The three sessions covered the following topics;
- Deploying UCP. This involved the following tasks;
- deploy the UCP controller to the first node
- add two further nodes as compute nodes
- integrate UCP with DTR and test by pulling/pushing an image using both CLI and the UCP GUI (including certificate setup)
- Managing container workloads in UCP. This involved the following tasks;
- add two nodes to an existing UCP controller
- deploy several nginx containers and a tomcat instance using UCP (varying port mappings)
- deploy a simple application using Docker Compose (still done via CLI, though integration is on roadmap). Used projects on GitHub. Cloned to local directory and then ran using Compose.
- User management and troubleshooting UCP. This involved the following tasks;
- create multiple users and groups via UCP
- assign rights to those users and groups in UCP
- create containers and assign and test permissions (using labels) in UCP
- create containers via Docker Compose & using labels (CLI)
- configure UCP to authenticate via an LDAP directory
- reset the ‘admin’ account password
Each course begins and ends with a candidate assessment using Trueability.com, the idea being that you can measure your learning via the course. I like the idea but either due to product issues or Trueability idiosyncrasies the assessments didn’t really seem to work too well. I’m sure those issues will be ironed out by the time the courses are finalised.
Thoughts on the training and the product
The training content was good, as was the instructor, but the product felt quite basic and raw, which I guess is to be expected for a beta course on a new product. UCP seems to be a thin UI built on top of the Docker Engine/Swarm/Compose trio, and its integration could be more comprehensive. For instance;
- docker-compose commands must still be run from the CLI (either locally or via an authenticated remote client), although the running containers are shown in the UI.
- I and others got ‘Internal Server error 500’ when deploying a two container app via docker-compose. Rerunning the command a second time worked. The instructor had seen this behaviour previously and had fed info back to the developers as a bug but it’s not very reassuring given the simplicity of the task on a newly built infrastructure.
- browser support seemed finicky – Chrome didn’t work with UCP week 1 whereas Safari did, but I got the opposite in week two
- setting up overlay networking was also finicky and failed for several people. Creating networks in UCP is not refined – you have to type ‘overlay’ for network type instead of just a dropdown of available choices for instance
- the public docs were outright wrong in a few places
- deleting a network silently failed, simply because an app was defined as using it. There were no warnings, although the instructor was good at picking up these things.
- when a user with insufficient permissions tries to pull a container image in UCP it simply hangs, rather than giving ‘permission denied’ or an error message
- the version of the underlying Docker components was also quite picky – several spurious errors were finally tracked down to running with a slightly old version of Docker Engine (1.9.1 rather than 1.10) and likewise with Docker Compose.
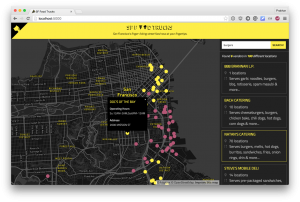
There’s a useful multi-container app in the Docker Github repository which was used as our trial app when using Docker Compose, but there’s nothing stopping you using it anytime you like. I really liked the cool SF FoodTruck app which we deployed during the course and it’s freely available on Github and was a good demonstration of how effective this method of deployment can be.
The post course assessment wasn’t really working but promises to be a nice feature – at least until formal certification becomes available. In general post course assessments aren’t worth having – either you can do the job or you can’t. Seriously though, how long can it be before you can be Docker Certified, maybe a Stevedor? 😉
In reality 12 hours of training, including lab work, isn’t going to cover much and there’s tons of complexity which we didn’t touch. I’m hoping to spend some more time with the product and experiment with some additional features, which I’ll write up here if I find the time.
As always I’d love to hear from anyone else with experience of Docker Datacenter. What do you think of it? Let me know in the comments or on Twitter.

 f you’re in the market to take a VMware certification exam, there’s some good news – provided you’re quick. For the next couple of days (while VMworld US is running, August 30th-4th September 2015) you can book VCP and VCAP/VCIX exams at a cool 25% off – even if you’re not at the conference! Like last year it’s only 25% (in earlier years it was 50% and if you’re attending the conference in person it still is) but every little helps.
f you’re in the market to take a VMware certification exam, there’s some good news – provided you’re quick. For the next couple of days (while VMworld US is running, August 30th-4th September 2015) you can book VCP and VCAP/VCIX exams at a cool 25% off – even if you’re not at the conference! Like last year it’s only 25% (in earlier years it was 50% and if you’re attending the conference in person it still is) but every little helps.

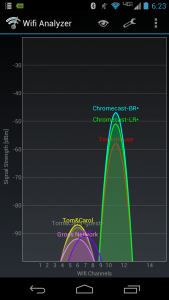 However I have noted a few issues, notably with their use of wifi. When you first plug in the Chromecast it’s in ‘master’ mode which means it acts as an access point, thus allowing you to join its wireless network with a tablet and configure it (and also opening up
However I have noted a few issues, notably with their use of wifi. When you first plug in the Chromecast it’s in ‘master’ mode which means it acts as an access point, thus allowing you to join its wireless network with a tablet and configure it (and also opening up